Anouncement
Anouncement

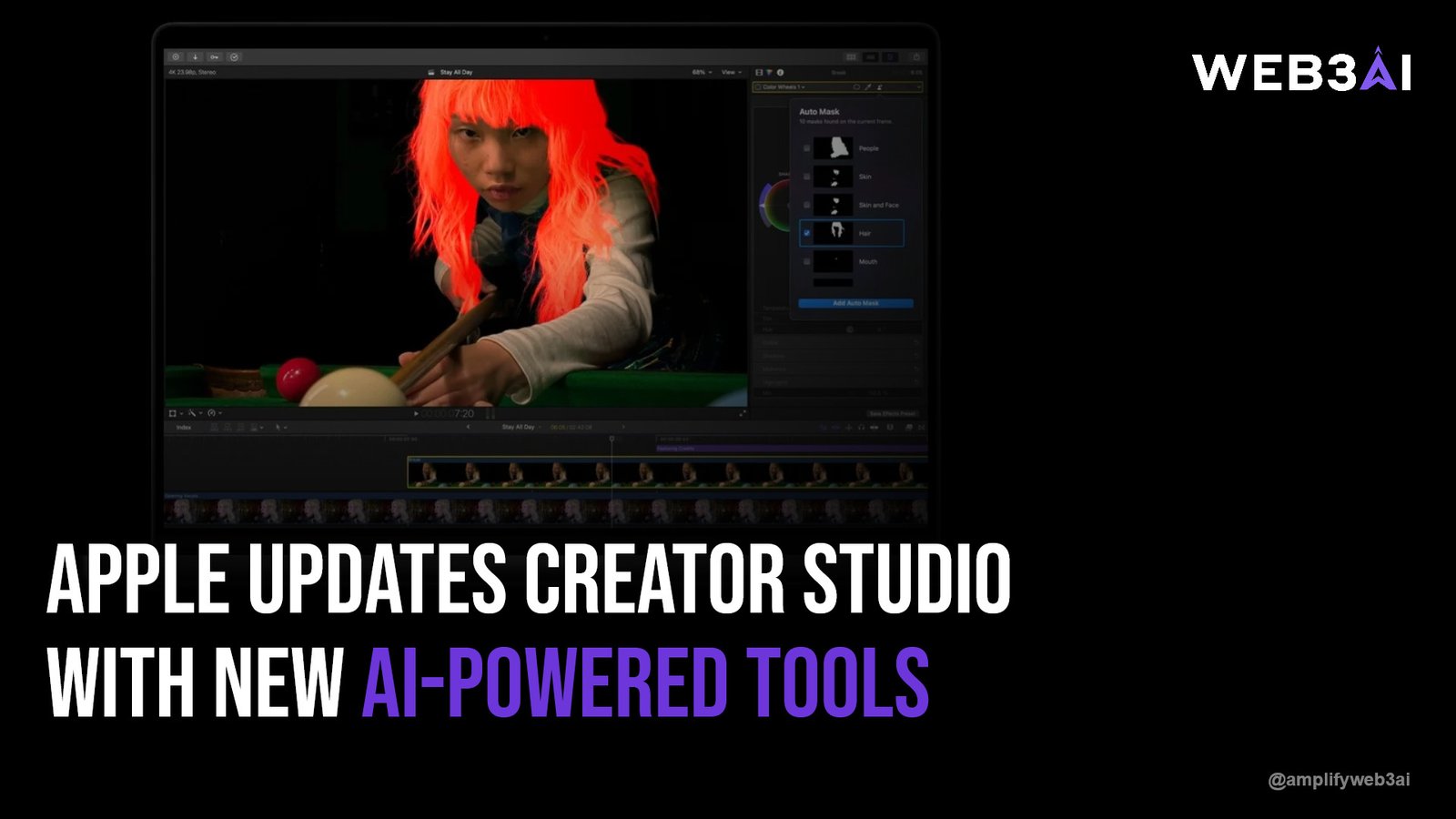
Google Gemini video generation AI took a significant leap forward at Google I/O 2025, and if you work in content, marketing, or media, this is the moment you’ve been watching for. Google unveiled new Gemini models — including Gemini 2.5 Flash and a revamped Omni architecture — that bring native video understanding and generation into one seamlessly unified system. This isn’t just a product update; it’s a signal about where AI-powered creativity is heading at speed.
For context on just how fast this space is moving, TechCrunch’s coverage of Gemini 2.5 Flash highlights that Google’s latest model family is being positioned as the most capable and cost-efficient in its history — with multimodal reasoning baked in from the ground up. Creators, developers, and enterprises are all paying close attention. The question is no longer whether AI will reshape video production, but how quickly you can adapt to use it well.
In this post, we break down exactly what Google announced, why the Gemini Omni and Flash updates matter for real-world creators, and what the practical implications are for anyone building content or products in 2025.
At Google I/O 2025, Google pulled back the curtain on several interconnected Gemini updates that collectively represent a new chapter for AI video. The headline addition was the Gemini Omni model — a next-generation architecture designed to process and generate across text, image, audio, and video simultaneously. Unlike earlier multimodal models that handled these modalities in sequence, Omni treats them as native, equal inputs and outputs.
Alongside Omni, Google refreshed Gemini 2.5 Flash — a lighter, faster model optimized for speed and cost efficiency. Flash is already deployed in Google’s consumer products and developer APIs, meaning these improvements are landing in real workflows immediately. Together, the two models cover opposite ends of the capability spectrum: Omni for depth and complexity, Flash for velocity and scale.
One of the most striking demos at I/O showed Gemini Omni taking a raw video clip as input, analyzing its content with human-level reasoning, and generating a contextually relevant edited version — complete with narration suggestions. That’s a workflow that previously required a team of editors, scriptwriters, and voiceover artists working across multiple specialized tools.
Pro Tip: If you’re a solo creator or small team, Gemini 2.5 Flash is likely your most practical entry point right now — it’s faster, cheaper to run via API, and already integrates with Google Workspace and NotebookLM for document-to-video workflows.
Understanding what makes Google Gemini video generation AI different requires looking under the hood — but in plain language. Traditional video AI systems were siloed: one model transcribed audio, another analyzed frames, a third generated text descriptions. Gemini Omni collapses this pipeline by training a single model to understand and generate across all these modalities at the same time.
In practice, this means you can provide Gemini with a 10-minute interview video and ask it to produce a 60-second highlight reel, a written summary, and a set of social-ready captions — all in a single prompt. The model understands what’s visually happening on screen, who is speaking, what’s being said, and how it all connects. This kind of contextual awareness across time (understanding that something said at minute 3 relates to something shown at minute 7) is genuinely new territory.
For brands and media companies, the implications are enormous. Content repurposing — turning a single long-form video into multiple short-form assets — is one of the most time-consuming tasks in modern marketing. Gemini Omni compresses that workflow from hours to minutes. We’ve been tracking this evolution closely because it directly intersects with what we build at amplifyweb3.ai. Learn more about how AI is already reshaping this space in our deep dive on how AI is transforming content creation — the principles there apply directly to what Gemini is now making possible at scale.
Google is now running two distinct Gemini lines in parallel, and choosing between them depends on your use case. Here’s a clear breakdown:
If you’re just getting started with AI video tools, Flash gives you an incredibly powerful on-ramp. If you’re building production workflows that need true multimodal intelligence, Omni is where you should be directing your attention — and your R&D investment.
Pro Tip: Don’t try to adopt both models at once. Start with Flash for one specific repeatable task in your workflow — like auto-generating social captions from long-form video — measure the time savings, then expand from there.
The arrival of capable Google Gemini video generation AI doesn’t just add another tool to the creative stack — it shifts the baseline expectation for what a solo creator or small team can produce. When a single AI model can ingest raw footage and output polished, contextually aware content variations, the creative bottleneck moves from production to ideation and strategy.
This is a meaningful shift. For years, the conversation around AI in creative work centered on text. Then images. Now video — the most resource-intensive format in content — is entering the same automation arc. The creators and brands who will win in this environment are those who treat AI as a creative collaborator, not just an efficiency tool. That’s exactly the lens we apply across our platform. For a broader look at the tools reshaping this moment, our overview of the rise of generative AI tools for creators is essential context.
Google’s I/O announcements don’t exist in a vacuum. OpenAI’s Sora has been the most-discussed AI video model over the past year, while startups like Runway, Pika, and Kling have been carving out serious creator audiences. What Gemini brings that most competitors lack is deep integration with Google’s existing ecosystem — Search, Workspace, YouTube, and Android — giving it distribution advantages that pure-play AI video companies simply cannot match.
The multimodal angle is also where Google has been investing most heavily, and it shows in Omni’s architecture. While Sora focuses primarily on text-to-video generation, Gemini Omni is designed for understanding and transforming existing video — a fundamentally different and arguably more commercially useful capability for most businesses. The ability to work with your existing content library, rather than generating from scratch, is where enterprise ROI lives.
We’re also watching how this plays out for Web3-native creators and platforms — an intersection that’s accelerating fast. Our analysis of Web3 and AI in the future of the creator economy explores how decentralized ownership models and AI-powered tools are beginning to converge in ways that could fundamentally change how creators are compensated and how content is distributed.
You don’t need to wait for full Omni availability to start building with Gemini’s video capabilities. Here’s a practical sequence to get started:
Google Gemini video generation AI refers to the capabilities within Google’s Gemini model family — particularly Gemini Omni — that allow the AI to understand, analyze, and generate video content. Unlike earlier AI systems that processed video in isolated steps, Gemini Omni handles text, audio, images, and video simultaneously within a single model, enabling contextual, cross-modal reasoning across an entire video’s timeline.
Gemini Omni is the deeper, more capable model designed for complex multimodal tasks — including generating and transforming video with full contextual understanding. Gemini 2.5 Flash is optimized for speed and cost, making it ideal for high-volume tasks like auto-captioning, summarization, and quick content analysis. Most creators will start with Flash and graduate to Omni as their workflows mature.
Google AI Studio offers a free tier that includes access to Gemini 2.5 Flash with video understanding capabilities. There are usage limits on the free tier, but it’s sufficient to experiment with real workflows. Full access to Gemini Omni’s video generation features is rolling out through Google’s product suite and Vertex AI, with pricing tied to enterprise agreements and API usage volume.
Sora is primarily a text-to-video generation tool — it creates new video from written prompts. Gemini Omni is built around understanding and transforming existing video, which makes it more useful for businesses working with real-world content libraries. Both have distinct strengths, but Gemini’s integration with Google’s broader ecosystem gives it unique distribution and workflow advantages for teams already using Google Workspace or YouTube.
Content marketers, video producers, social media teams, and educators will see immediate value — especially those managing large libraries of long-form content that need to be repurposed into shorter formats. Developers building AI-powered media tools and platforms will also benefit from the Gemini API’s multimodal capabilities. As Omni access expands, independent creators and small studios will gain capabilities that were previously reserved for enterprise teams.
Google Gemini video generation AI represents one of the most consequential developments in the creative technology space in 2025. What Google unveiled at I/O — the Omni architecture’s native multimodal reasoning and Flash’s efficiency at scale — isn’t an incremental update. It’s a new foundation for how video content is understood, created, and distributed by anyone with access to an API key. The creative workflows that felt cutting-edge 12 months ago are already being compressed and automated, and the creators who lean into this moment will build lasting advantages over those who wait.
At amplifyweb3.ai, we believe the intersection of AI, Web3, and the creator economy is where the most interesting work is happening — and Gemini’s video capabilities are a major piece of that puzzle. The tools are here. The question is how you choose to use them. Explore what we have built at attn.live.